



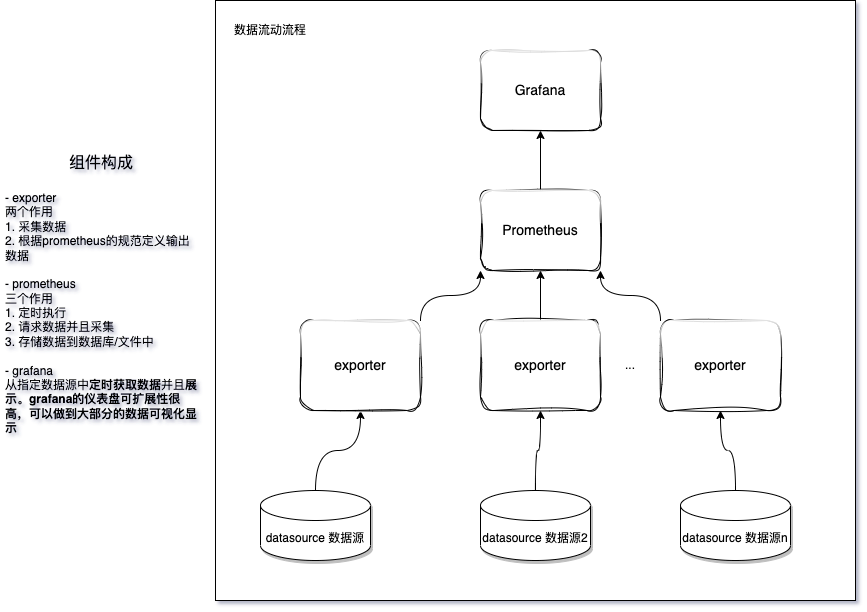
整体架构
部署
博主使用的是docker compose进行部署, 编辑完成docker-compose.yaml文件后启动即可
docker compose 启动后台服务命令
docker compose up -d
示例 docker-compose.yaml 文件
version: '3.4'
services:
prometheus:
image: prom/prometheus
container_name: prometheus
#设置容器中的hostname,同个网络之中的容器可以通过hostname找到对应容器
hostname: prometheus
ports:
- 9090:9090
volumes:
# prometheus 配置文件
- /XX/prometheus.yml:/etc/prometheus/prometheus.yml
# 同步容器和宿主机时间戳
- /etc/localtime:/etc/localtime:ro
prometheus-exporter:
# 网上有很多已经构建的exporter供下载使用,这里使用容器化exporter,如果需要宿主机的数据可以通过挂载或者物理部署的方式
image: prom/node-exporter
container_name: node-exporter
hostname: node-exporter
ports:
- 9100:9100
volumes:
- /etc/localtime:/etc/localtime:ro
grafana:
image: grafana/grafana
container_name: grafana
hostname: grafana
ports:
- 3010:3000
volumes:
- /etc/localtime:/etc/localtime:ro
- /XX/grafana.ini:/etc/grafana/grafana.ini
grafana.ini 配置文件参考 Grafana Github
示例 prometheus 配置文件
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration 配置监控报警
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
# 这里是主要配置数据源的地方,即获取各种exporter的数据进行定时采集整理
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics',配置数据获取路由
# scheme defaults to 'http',请求协议配置
static_configs:
- targets: ["prometheus:9090"] #配置请求地址和端口
# 配置抓取的数据
- job_name: "node_test"
static_configs:
- targets: ["prometheus-exporter:9100"]
# 每个target会作为grafana中的host或者instance显示
Q.E.D.